感谢韩顺平老师的网课!
韩顺平老师Java基础
基础知识
字符串转对应的数据类型, 需要相应的方法
Integer.parseInt
Double.parseDouble
字符串转字符:取出字符串第一个字符:s.charAt(0)
算术运算符
%: 取余的本质在于公式:a%b=a-a/b*b,因此即使是负数也是可以取余的。注意:当a为浮点型时,有一步要强转成整数进行计算,此时 a%b=a-(int)a/b*b
- &&:短路与
- 当第一个条件为假时,&&不会进行下一条件的判断,&会把下一条件判断完
- 因此常用&&
swicth:
- switch(num),这个变量num的类型仅限于byte,short,int,rnum,char,string六种数据类型
- 写在case后的常量类型,要与num类型相同,或者,可以向num的数据类型兼容
- 若当前case满足条件且未设置break,则会忽略下面的case,穿透执行里面的语句,直至遇到下一个break。利用这个性质,可以设置多个case,满足其中一个case时,输出他们共同的输出语句。
可变参数有以下需要注意的点:
- 可变参数可以和普通参数共同作为函数的形参,但可变参数必须放在末尾
- 在一个函数的形参中,可变参数只能有一个
1
2
| 数据类型... 数据名
例:int... num
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| this(实参值)
例:
public person(){
this("syx",23);
System.out.println("这是person()构造器");
}
public person(String name,int age){
System.out.println("这是person(String name,int age)构造器");
this.name=name;
this.age=age;
}
|
注意:this访问构造器,只能在一个构造器内访问另一个构造器,且必须写在开头位置
类变量 用来类实例的共享
类方法注意点
- 静态方法内部无法使用this,super
- 静态方法无法调用非静态成员,而普通方法既可以调用非静态成员,也可以调用静态成员(成员包含了类中的属性,方法)
代码块
普通代码块和静态代码块
生成对象时,其类中的调用顺序
- 静态代码块和静态成员属性的初始化,若两个同时存在或有多个,根据定义顺序来调用
- 普通代码块,普通成员变量初始化
- 构造器
在继承情况下,生成对象类中的调用顺序
- 父类的静态代码块和静态成员属性的初始化
- 子类的静态代码块和静态成员属性的初始化
- 父类的普通代码块和普通成员属性初始化
- 父类构造器
- 子类的普通代码块和普通成员属性初始化
- 子类的构造器
单例模式:保证类只有一个对象——懒汉式和饿汉式
懒汉式缺点:多线程下可能会出现问题,同时进入类方法的if语句,从而创建了多个类对象
final修饰符:不给修改和继承 ,一般在定义的时候赋值,也可以在构造器或代码块内赋值
接口:转换器
实现接口:实现接口定义的方法
接入接口:通过接口调用方法
jdk8之后,接口有抽象方法,静态方法,默认实现方法
项目经理设计接口
一个普通类实现接口就必须将该接口的所有方法都实现。抽象类实现接口,可以不用实现接口的方法
一个类可同时接入多个接口,即要实现多个接口的所有方法
接口所有的属性都是public static final的—— 接口属性访问:接口名.属性名(静态)
类不能多继承但接口可以继承多个接口,接口不能继承其他类
如果子类需要扩展功能可以通过实现接口的方式来拓展
属性 方法 构造器 代码块 内部类
内部类最大的特点就是可以直接访问私有属性,并且可以体现类与类之间的包含关系
根据定义在外部类的位置类上
局部内部类(有类名)
1. 定义在外部类的局部位置 可以访问外部类的所有成员,包括私有成员
2. 不能添加访问修饰符,其地位是一个局部变量,但可以用final修饰——意味着不能被继承
3. 作用域:仅仅在定义他的代码块或方法体内(局部变量)
4. 局部内部类直接访问外部类成员
5. 外部类在方法中创建内部类的实例,再去访问内部类的成员
6. 如果内部类成员与外部类成员重名时,默认就近原则,如果想访问外部类成员:
(外部类)名.this.成员去访问
匿名内部类(无类名)
- 本质是个类,内部类,没名字(表面上),是个对象
- 基于接口的内部类:简化开发,只使用一次
- 基于类的匿名内部类,重写原来类的方法,但不用子类的继承去重写
- 匿名内部类的作用在于,一般要实现接口的方法或是类的抽象方法时,都需要新写一个类来implements/extends,才能够进行重写,后面若不再用,会造成资源浪费,而匿名内部类弥补了这一缺点,而且很便捷
- 把匿名内部类当作方法的实参(实现了接口的对象),形参类型是接口类型
1
2
3
4
5
6
| f1(new IL() {
@Override
public void show() {
System.out.println("这是一副名画~~...");
}
});
|
成员内部类(没有static):
- 定义在成员的位置,可以加修饰符——地位等同于成员
- 内部类依旧直接访问外部类所有成员
- 外部类访问内部类需要创建对象再访问
- 外部其他类可以访问成员内部类
- 用外部类对象实例化:
Outer.Inner inner = outer.new Inner(),outer是Outer的实例
- 在外部类中编写一个方法,返回一个内部类的实例
静态成员部类(static)
- 可以访问外部类所有静态成员,包括私有的,不能访问非静态成员
- 可以加修饰符——成员地位
- 内部类访问外部类成员直接:外部类.成员名,因为静态内部类只能访问静态成员
- 外部其他类可以访问成员内部类
Outer.Inner inner = Outer.new Inner()- 编写方法返回静态内部类的实例
枚举和注解
枚举
枚举类——枚: 一个一个 举: 例举 , 即把具体的对象一个一个例举出来的类
特点:只读,不需要修改
一组有限的特定的对象, 变量名一般大写(常量规范)
自定义枚举类:
- 将构造器私有化
- 去掉setXXX方法
- 在类内部直接
new新对象,对外暴露对象——public static final
- 最后可以用
final优化
enum关键字实现枚举注意事项
- class 改成 enum
- 直接使用常量名(构造器传参)
- 多个常量对象用都好隔开,最后一个有分号,并写在行首
- 如果使用无参构造器 创建 枚举对象,则实参列表和小括号都可以省略
- 因为枚举类隐式地继承了Enum类,因此不能再继承其他类
- 枚举类也是类,可以实现接口
父类enum的一些方法
name() 返回当前枚举对象的名字——指的是变量名,如果直接输出枚举对象默认用的toString方法,具体实现看toString的方法体
ordinal()返回当前类名在枚举对象的定义顺序,从零开始
values()返回一个枚举对象的数组
1
2
3
4
| Season3[] values = Season3.values();
for(Season3 season:values){
System.out.println(season);
}
|
valuesOf()将括号里的字符串转为枚举类象名字去查找,若存在则返回对象,否则报错
compareTo()将枚举对象和括号内的枚举类象进行序号的比较,编号1 - 编号2
注解
@Override : 重写父类方法,只用于方法。显性标注则会在编译时检查语法是否正确
@Deprecated: 表示已过时
@SuppressWarning: 压制警告,可以将编译器中给出的警告消除掉
异常
运行异常 编译异常
try-catch-finally 和 throws二选一 运行异常默认有throws
TCF细节
- catch部分可以不写,即只有try-finally,这么做的话,因为没有catch语句,即使获取错误也不会处理,而是直接报错,其目的就在于在报错前执行finally语句
- 选中认为会出现异常的语句,按ctrl+alt+t。选择try catch语句,即可自动生成该格式
- 可调用多个catch来防止多重异常,但父类Exception必须写在最后一个,且碰到一个错误就会返回异常,并不会将所有错误检测出,相当于建立了多重墙,并返回首个异常
throws细节
- 写在方法后面,可以抛出多个异常,用逗号分隔
- 当抛出的是运行异常时,即使不在方法后显示地写出
throws 异常名,系统也会自动抛出,这也就解释了平时没有在函数后面写throws关键字,最后运行时还可以告诉我们异常,是由JVM输出的
1
2
3
4
5
6
| public static void f1(){
f2();
}
public static void f2() throws ArrayIndexOutOfBoundsException{
}
|
- 当抛出的是编译异常时,必须显式地调用
throws 异常名,否则无法传给调用该方法的方法
1
2
3
4
5
6
7
8
9
10
11
12
13
| public static void f4() throws FileNotFoundException {
}
public static void f3() throws FileNotFoundException {
f4();
}
public static void f5(){
try {
f4();
} catch (FileNotFoundException e) {
throw new RuntimeException(e);
}
}
|
- 当子类重写了父类的方法并且在这两个方法中都抛出了异常时,子类抛出地异常类型必须和父类相同,或者是父类异常类型的子类
自定义异常
1
2
3
4
5
6
7
8
| class AgeExecption extends RuntimeException{
public AgeExecption(String message) {
super(message);
}
}
使用:
throw new AgeExecption("年龄超出范围");
|
注意:这里用到的是throw,和上面的throws是两个东西,下面将进行区分
| 名字 |
使用位置 |
后面跟的 |
作用 |
| throws |
方法体()后 |
异常类名 |
抛出异常,返回给调用它的函数 |
| throw |
方法体内 |
异常类对象 |
返回异常,一般结合try语句,到这句就交给catch |
|
|
|
|
常用类
Wrapper
八大包装类,除下面整型变化其他就是首字母大小写的变化。 六个数类的父类是Number类
- int -> Integer
1. 包装类和基本数据类型的转换
装箱与拆箱
jdk5之后可以自动开箱自动装箱
1
2
| Object obj = true : Integer(1) : Double(2);
|
2.包换类和String的相互转换
1
2
3
4
5
6
7
8
| Integer i = 100;
String s = i + "";
String s1 = i.toString();
String s2 = String.valueOf(108);
String s3 = "234"
Integer int1 = Integer.parseInt(s3);
Integer int2 = new Integer(s3);
|
注意:只要有基本数据类型, ==就是判断值相不相等
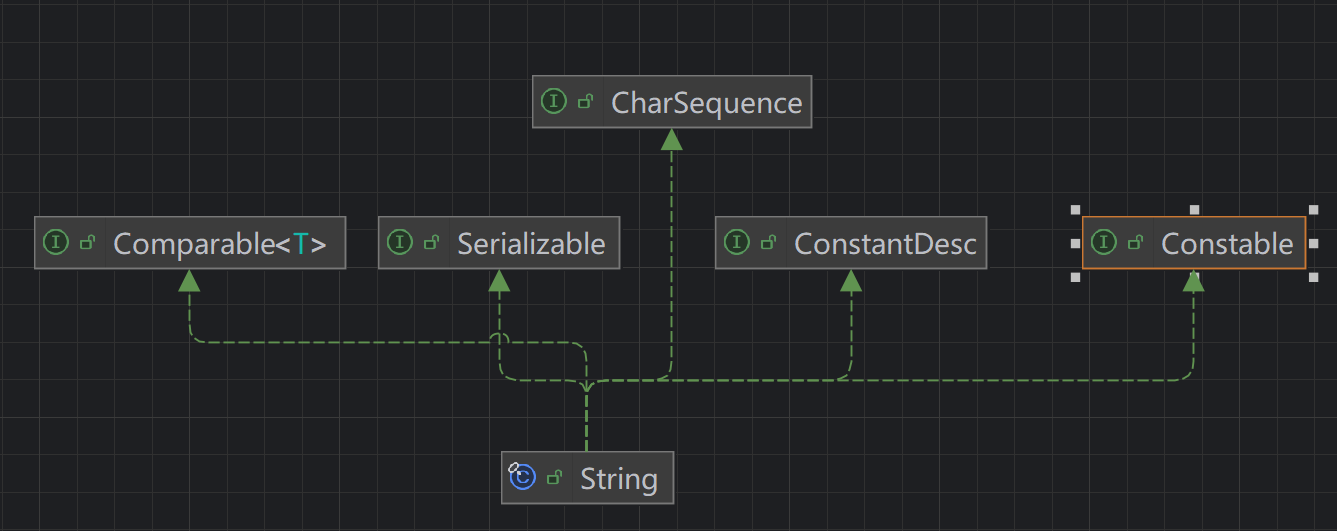
- String类实现了Serializable接口,表明其是可串行化的(可以在网络上传输)
- 字符串用utf8编码,不区分字母和汉字都是两个字符
- String类实现了comparable接口,表示是可比较的
- 用final修饰,是最终类,不能被继承
- 在底层(本质)是一个char数组 —— private final char value[] 不可以修改(value 的地址不能修改)但是单个字符的内容可以变化。
字符串两种创建方式的 区别
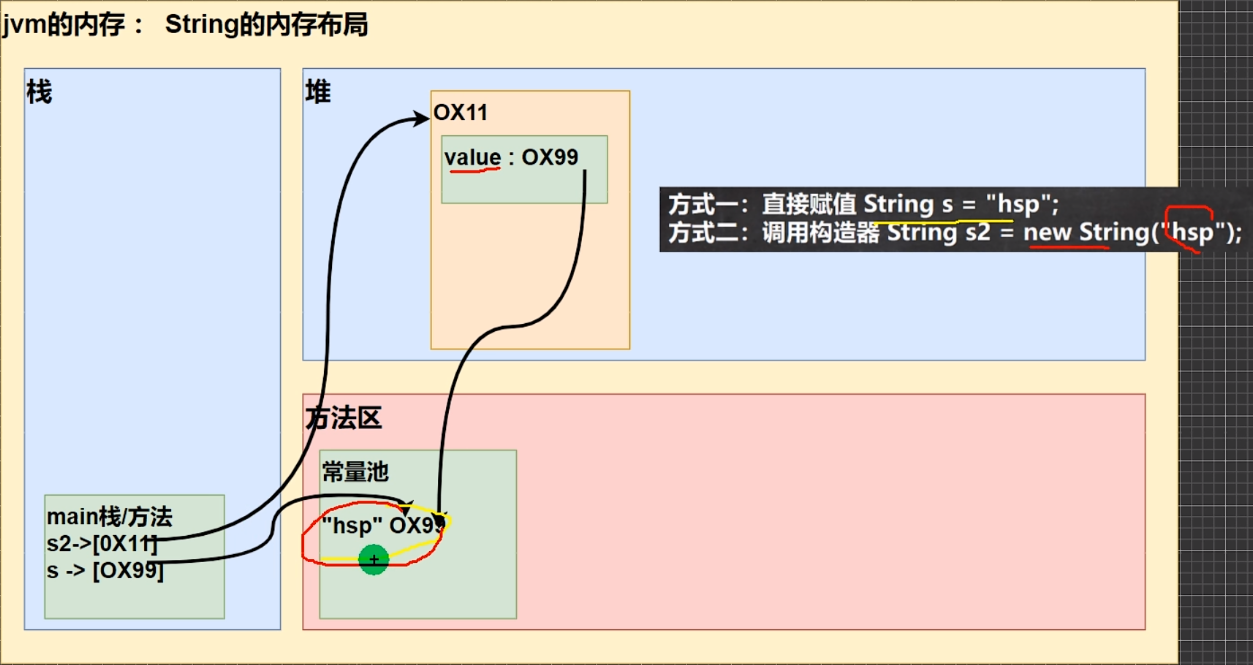
字符串特性
字符串常量相加,最后返回的字符串指向的是常量池中的地址。字符串变量相加,最后返回的字符串指向的是堆中的地址
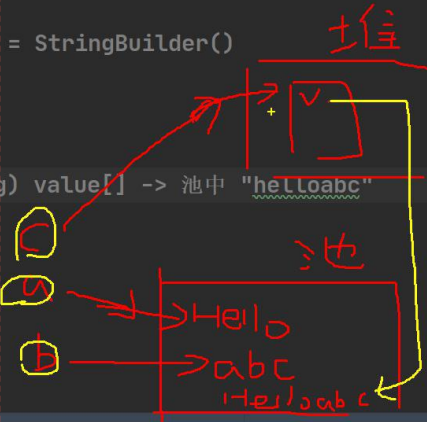
String和StringBuffer对比
- StringBuffer类的数组value是存储在堆中的,而String类的字符串一般存储在常量池中(构造器方法虽然对象在堆中,但其value数组还是指向了常量池中的具体值)
StringBuffer常用构造器:
1
2
3
| StringBuffer stringBuffer = new StringBuffer();
StringBuffer stringBuffer = new StringBuffer(int cap);
StringBuffer stringBuffer = new StringBuffer(str);
|
转换
1
2
3
4
5
6
7
|
String s1 = "hello";
StringBuffer sb = new StringBuffer(s1);
StringBuffer sb1 = new StringBuffer().append(s1);
String s2 = sb1.toString();
String s3 = new String(sb1);
|
常用方法
1
2
3
4
5
|
s.replace(9,11,"周芷若");
s.insert(9,"赵敏")
|
StringBuilder
- StringBuilder不是线程安全的,单线程最优选。方法基本和StringBuffer一样
- StringBuilder的方法,没有做互斥的处理,即没有synchronized关键字,因此在单线程的情况下使用
String、StringBuffer和StringBuilder的比较
- 就执行速度而言,StringBuilder > StringBuffer > String,String慢的原因在于每次赋新值都是创建新的对象(只有在同名时才不会)(存储的是字符串常量),效率很低。而StringBuffer和StringBuilder存储的是字符串变量,直接进行原地修改即可,效率高,而StringBuilder因为使用场景是单线程,速度最快
- 就安全性而言,StringBuffer>StringBuilder,因为StringBuffer使用场景是多线程,线程保护机制比StringBuilder要强(体现在其方法都用synchronized进行修饰)
三种String类的适用场景:
- 若字符串不需要经常修改,且多个对象使用的是同一个字符串变量名(会直接指向常量池中的同名字符串),就用String类。String类的复用性很高
- 若字符串需要经常修改,且运行在多线程环境下,就用StringBuffer类
- 若字符串需要经常修改,且运行在单线程环境下,就用StringBuilder类
常用类
Array类 静态方法,数组直接用
System类
Date类
第一类获取时间的形式:
1
2
3
4
5
6
7
8
9
10
11
| Date date=new Date();
System.out.println(date);
SimpleDateFormatter sdf=new SimpleDateFormat("yyyy年MM月dd日 HH:mm:ss");
String s1=sdf.format(date);
|
BigInteger大数据类: 加减乘除用对应的方法。 还有高精度浮点类 BigDecimal
Calendar类:抽象类,无法被实体化,仅能通过getInstance(其类中定义的public static方法)获取类对象
1
2
3
4
5
6
7
8
9
| Calendar c1=Calendar.getInstance();
System.out.println(c1.get(Calendar.YEAR));
System.out.println(c1.get(Calendar.MONTH)+1);
System.out.println(c1.get(Calendar.DATE));
System.out.println((c1.get(Calendar.HOUR)+12)%24);
System.out.println(c1.get(Calendar.HOUR_OF_DAY));
System.out.println(c1.get(Calendar.MINUTE));
System.out.println(c1.get(Calendar.SECOND));
|
LocalDateTime类:线程安全
其下还包含了LocalDate和LocalTime类,LocalDateTime类是最全的,返回年月日时分秒
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| LocalDateTime a=LocalDateTime.now();
System.out.println(a.getYear());
System.out.println(a.getMonth());
System.out.println(a.getMonthValue());
System.out.println(a.getDayOfMonth());
System.out.println(a.getHour());
System.out.println(a.getMinute());
System.out.println(a.getSecond());
LocalDateTime a1=a.plusYears(25);
DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy年MM月dd日 HH:mm:ss");
LocalDateTime a=LocalDateTime.now();
String s1=dateTimeFormatter.format(a);
System.out.println(s1);
|
集合
集合体系图【背!!!】
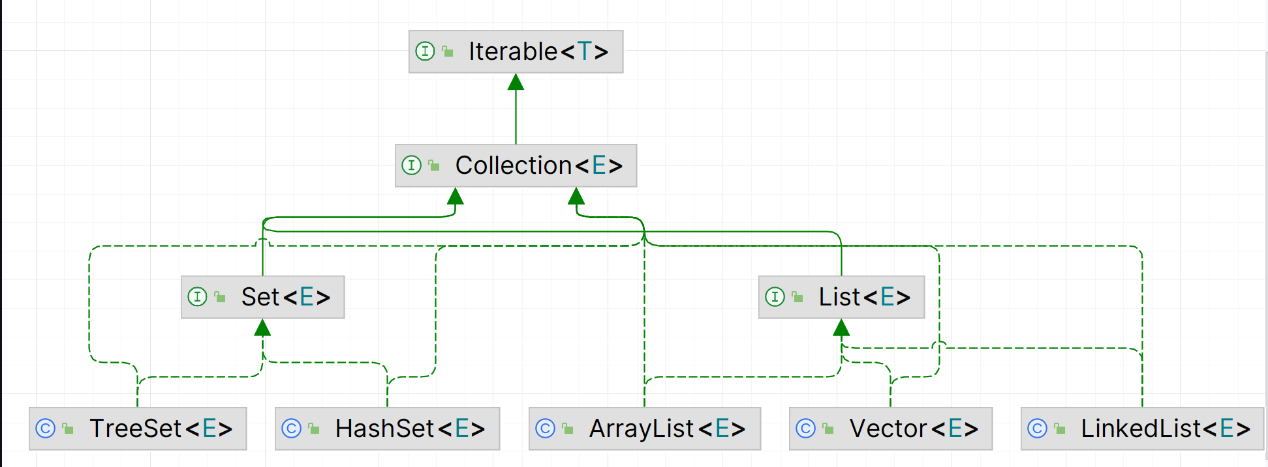
Collection 和 Map
Collection 每次记录单个元素,Map记录的是键值对
Collection接口
1
2
3
4
5
6
7
8
9
10
|
add(), remove(), isEmpty(), size(), contains()
ArrayList arrayList = new ArrayList();
arrayList.add("红楼梦");
arrayList.add("西游记");
list.addAll(arrayList);
System.out.println(list.contains("三国演义"));
System.out.println(list.containsAll(arrayList));
|
用迭代器遍历集合
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| Iterator iterator = col.iterator();
while (iterator.hasNext()){
Object obj= iterator.next();
System.out.println(obj);
}
Collection col=new ArrayList();
col.add(new Book("三国演义","罗贯中"));
col.add(new Book("红楼梦","曹雪芹"));
for(Object object:col){
System.out.println(object);
}
|
- 生成迭代器循环遍历的快捷指令
itit
- 查看所有快捷指令
ctrl+j
List接口
存储数据是可重复的,有序的,实现了Collection接口,常用方法和Collection类似
ArrayList数组无参扩容规则:
1. 初始化ArrayList对象,数组elementData(底层存储)容量为0
2. 添加第一个数据之后扩容为10
3. 而后每超出容量扩容1.5倍
有参对象的类似:
1. 初始化ArrayList对象时,数组elementData的容量为初始化时设置的参数
2. 每当容量达到上限,扩充为当前容量的1.5倍
Vector类的无参对象初始化和扩容规则:
1. 初始化类对象时,就分配10的数组空间
2. 后续扩容时,每次更新的容量都是原容量的两倍
带参类似
ArrayList和Vector的比较
| 类名 |
适用场景 |
初始化机制 |
扩容机制 |
| ArrayList |
单线程 |
无参:初始长度为0,插入第一个元素之前,数组扩容为10。带参:初始长度为指定长度 |
扩充为当前容量的1.5倍 |
| Vector |
多线程,其方法都有synchronized |
无参:初始长度为10。带参:初始长度为指定长度 |
扩充为当前容量的2倍 |
|
|
|
|
LinkedList类
底层实现的双向链表,增删方便
LinkedList和ArrayList的比较
| 类 |
底层存储数据 |
使用场景 |
安全性 |
| LinkedList |
双链表 |
增删用的比较多时 |
不安全 |
| ArrayList |
可变数组 |
改查用的比较多时 |
不安全 |
Set接口
无序,不能用索引,取出顺序与存放顺序不同,但取出顺序是固定的。
HashSet
创建HashSet时,底层创建的是HashMap,因此本质研究的是HashMap的底层数据结构,底层实现数组+链表
HashSet扩容机制:
- 向table里面放数据,数据哈希值(改哈希值不是真正的,通过>>>16计算出来的)对应索引的数组没数据直接放。
- 有数据就用equals方法(重写)再放,
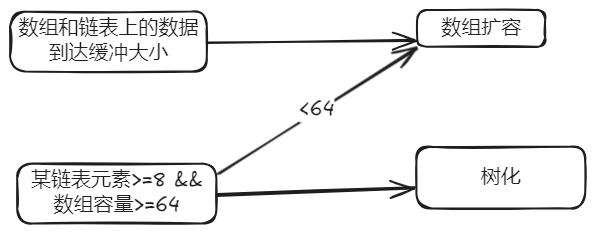
- 在java8中,一条链表元素到达设定值(默认为8),并且table的容量大于等于64就会树化(红黑树),否则就继续扩容。
- 注意:有设置一个缓冲值threhold= 当前容量$*$因子(0.75),数据个数达到这个数就会扩容(不论是在table的还是在链表上的)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
|
LinkHashSet
数据结构为table数组+双向链表,拥有头尾指针,每个节点也有头尾指针,有顺序不允许添加重复元素
重写equals方法可以利用IDEA的封装调用
存储数据的底层实现:
- 初始扩容16容量
- 当达到门槛值的75%时,进行扩容,扩容为当前容量的两倍
Map接口(JDK8)
键值对,和collection接口平行(即不属于collection)
- 键不可重复,若对重复的键赋予不同的值,新值会覆盖旧值
- 值可以重复
- 键可以为空,但只能有一个空。值可以为空,不限个数
- 可通过键找到值
- 存储的键和值可以是任何引用型类型,会存储在HashMap$Node对象中。Node是HashMap的一个静态内部类,包含hash值,键值对,下一元素的指针等,可将链表进行连接
Map常用方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
HashMap hashMap = new HashMap();
hashMap.put(1,"syx");
hashMap.put(null,"syx");
hashMap.put(2,"wanke");
hashMap.put(3,"add");
Object object = hashMap.get(3);
System.out.println(object);
Object remove = hashMap.remove(2);
System.out.println(hashMap);
boolean empty = hashMap.isEmpty();
System.out.println(empty);
boolean b = hashMap.containsKey(null);
System.out.println(b);
System.out.println(hashMap.size());
hashMap.clear();
System.out.println(hashMap);
|
Map六种遍历方式
一共有六种,细分的话就是三种,每种包含了for循环和迭代器循环两种方式,能够用迭代器,因为得到的集合都是实现了collection接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
System.out.println("法一:");
Set keyset = hashMap.keySet();
for (Object object :keyset) {
System.out.println(object+"-"+hashMap.get(object));
}
System.out.println("法二:");
Iterator iterator = keyset.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println(next+"-"+hashMap.get(next));
}
Collection values = hashMap.values();
System.out.println("法三:");
for(Object obj:values){
System.out.println(obj);
}
System.out.println("法四:");
Iterator iterator1 = values.iterator();
while (iterator1.hasNext()) {
Object next = iterator1.next();
System.out.println(next);
}
Set set1 = hashMap.entrySet();
System.out.println("法五:");
for (Object object :set1) {
Map.Entry object1 = (Map.Entry) object;
System.out.println(object1.getKey()+"-"+object1.getValue());
}
System.out.println("法六:");
Iterator iterator2 = set1.iterator();
while (iterator2.hasNext()) {
Object next = iterator2.next();
Map.Entry next1 = (Map.Entry) next;
System.out.println(next1.getKey()+"-"+next1.getValue());
}
|
HashMap底层机制
因为HashSet的底层实现就是HashMap,因此其底层的存储数据和扩容代码相同,唯一的区别在于HashMap在存储相同键不同值时,新值会把旧值覆盖,而HashSet是不允许存相同值
注:HashMap是线程不安全的
1
2
3
4
5
6
7
8
|
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
|
HashMap总结:
- 在创建对象时,底层生成HashMap$Node[] table数组,用于存储每个键值对(视为一个Node),初始数组容量为空
- 加入第一个数据之前,会触发数组扩容resize(),数组容量变为16,因子为0.75,门槛容量为12
- 后续继续添加k-v时,会根据key的hash值得到数组下标的索引,若索引处没有值,则直接加入,若索引处有元素,判断两个元素的key是否相等,相等则覆盖,不相等则考虑在后面的链表/红黑树上进行插入,在链表上插入时就会涉及扩容以及链表->红黑树机制
- 当一条链表上的元素>=8个时,会触发转为树的操作,不过在转为树之前会检查当前数组的长度是否>=64,若<64则进行数组扩容,容量变为原容量的两倍,若>=64则转换为红黑树
- 数组扩容还会在当前数组元素(包含链表上的元素个数)个数>=门槛数时触发
HashTable:
- HashTable是实现了Map接口的类,和HashMap是平行关系,方法基本和HashMap一样
- HashTable适用于多线程,其键和值都不能为空,否则抛出异常
- 初始化对象会创建HashTable[] table 数组,初始容量为11,加载因子0.75
- 扩容机制为:
当前容量 * 2 + 1
HashTable对比HashMap
| 类 |
适用场景 |
效率 |
键值对能否为空 |
初始数组容量 |
扩容机制 |
| HashMap |
单线程 |
高 |
可以 |
16 |
原容量*2 |
| HashTable |
多线程 |
低 |
不可以 |
11 |
原容量*2+1 |
| Properties: |
|
|
|
|
|
- Properties是继承了HashTable的类,因此其键值对也不能为空
- 多用于读写xxx.properties型的文件
Collections工具类
对各种集合(Set, List, Map)进行各种操作的工具类
和Collection区分,Collection是接口,Collections是类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
ArrayList arrayList = new ArrayList();
arrayList.add("jack");
arrayList.add("tom");
arrayList.add("tom");
arrayList.add("jerry");
System.out.println(arrayList);
Collections.reverse(arrayList);
System.out.println(arrayList);
for (int i = 0; i < 5; i++) {
Collections.shuffle(arrayList);
System.out.println(arrayList);
}
Collections.sort(arrayList);
System.out.println(arrayList);
Collections.sort(arrayList, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String)o1).length()-((String)o2).length();
}
});
System.out.println(arrayList);
Collections.swap(arrayList,1,2);
System.out.println(arrayList);
System.out.println(Collections.max(arrayList));
System.out.println(Collections.min(arrayList));
ArrayList desc = new ArrayList();
for (int i = 0; i < arrayList.size(); i++) {
desc.add("");
}
Collections.copy(desc,arrayList);
System.out.println(desc);
int tom = Collections.frequency(desc, "tom");
System.out.println(tom);
Collections.replaceAll(arrayList,"tom","汤米");
System.out.println(arrayList);
|
集合小结
TreeMap的去重
- 当我们为了使输出是有序的,这时会自定义排序方法,当排序规则得出
==时,就会去重。
- 当我们并没有自定义排序方法,即在创建TreeMap对象时调用的是空值构造器,系统内部也会自动调用一个比较器,这个比较器是基于当前输入数据类型的实现了Comparable接口的比较器,再使用其中的compareTo方法进行比较
- 也就是说,如果自己定义了一个类,却没有实现Comparable接口,那么该类的对象是无法插入进TreeMap类的对象的,底层在去重代码那一块向上转型为Comparable接口类型时会报错
泛型
传统做法问题:
不能对加入到集合的数据类型进行约束
向下转型的类型多,存在转换异常的隐患
泛型可以用于类,接口,集合的定义中,在实体化对象时将泛型的内容变为具体的数据类型
1
2
3
4
5
6
7
8
9
10
11
|
ArrayList<Dog> dogs = new ArrayList<Dog>();
dogs.add(new Dog("tom"));
dogs.add(new Dog("happt"));
for (Dog object :dogs) {
System.out.println(object);
}
|
由此可看出泛型的好处:
- 有效保证了程序的安全性,控制了输入数据的类型
- 跳过了向下转型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
class Person<E>{
E s;
public Person(E s) {
this.s = s;
}
public E f1(){
return s;
}
public void f2(E s){
System.out.println(s);
}
public void f3(){
System.out.println(s.getClass());
}
}
Person<String> person = new Person<String>("tom");
|
细节
只能传引用类型,不能传基本数据类型
指定泛型的类型之后,可以传入该类型以及子类
简写:
1
2
3
4
|
Pig<A> pig = new Pig<>(new A());
ArrayList ayy = new ArrayList();
|
自定义泛型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
class Tiger<T,R,M>{
String name;
R r;
M m;
T t;
T[] ts = new T[8];
public Tiger(String name, R r, M m, T t) {
this.name = name;
this.r = r;
this.m = m;
this.t = t;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public R getR() {
return r;
}
public void setR(R r) {
this.r = r;
}
public M getM() {
return m;
}
public void setM(M m) {
this.m = m;
}
public T getT() {
return t;
}
public void setT(T t) {
this.t = t;
}
}
|
- 泛型接口的泛型实体化,是在其被其他接口继承时,或是被类实现时。一旦实体化,其内部的泛型方法,属性都会自动变为具有实体化属性的形式,而不是再用泛型的字母代替
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
interface IA extends Iusb<String,Integer>{
}
class A implements IA{
@Override
public Integer get(String s) {
return null;
}
@Override
public void hi(Integer integer) {
}
@Override
public String f1(Integer integer) {
return IA.super.f1(integer);
}
}
interface Iusb<U,R>{
R get(U u);
void hi(R r);
default U f1(R r){
return null;
}
}
|
泛型方法:
1
2
3
4
| public <E> void f1(){E e}
public E f1(){}
public void f1(T t){}
|
泛型没有继承性,他就是一种限制
事件处理机制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
| public class event01 extends JFrame{
MyPanel mp=null;
public static void main(String[] args) {
new event01();
}
public event01(){
mp=new MyPanel();
this.add(mp);
this.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
this.setSize(800,800);
this.setVisible(true);
this.addKeyListener(mp);
}
}
class MyPanel extends JPanel implements KeyListener {
int x=10;
int y=10;
@Override
public void paint(Graphics g) {
super.paint(g);
g.fillOval(x,y,10,10);
}
@Override
public void keyTyped(KeyEvent e) {
}
@Override
public void keyPressed(KeyEvent e) {
if(e.getKeyCode()==KeyEvent.VK_UP){
y--;
} else if (e.getKeyCode()==KeyEvent.VK_DOWN) {
y++;
}else if(e.getKeyCode()==KeyEvent.VK_LEFT){
x--;
}else if(e.getKeyCode()==KeyEvent.VK_RIGHT){
x++;
}
this.repaint();
}
@Override
public void keyReleased(KeyEvent e) {
}
}
|
- 每次移动要手动刷新页面,即要加上
this.repaint()
- 画框也要实现对键盘的监听,即
this.addKeyListener(),因为画板实现了KeyListener接口,因此画板的实例化对象就是该接口的引用,可以作为参数加入addKeyListener()方法中
- 需要不断变化的参数,可以在初始时设置为变量
委派事件模型:事件发生和事件处理是靠一个事件对象关联起来的,
事件源(按钮,窗口)被触发(有事件【键盘事件,鼠标事件】发生)生成对象,事件监听者收到后做处理,事件对象有很多信息。
Cpu的并行和并发
线程
常见的创建线程有两种:继承Thread类,实现Runnable接口
继承Thread类,要重写其中的run方法,而这个run方法是在Runnable接口中定义的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| public class Thread01 {
public static void main(String[] args) {
Cat cat = new Cat();
cat.start();
}
}
class Cat extends Thread{
@Override
public void run() {
super.run();
int num=0;
while(true){
if(num==8)
break;
System.out.println("小猫叫");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
num++;
}
}
}
|
主线程和子线程:
主函数运行时所创建,名字为main
在主函数中创建的线程为子线程
二者可以交替运行,主线程的结束并不影响子线程的运行
通过实现Runnable接口创建线程
- 之前所学继承Thread类来创建线程对于java的单继承机制有限制,如果有一个类已经继承了另外一个类便失效了
- 同样的重写run方法
- Runnable没有
start方法,要通过创建实现了Runnable的对象,将对象传入Thread类中(代理模式)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| public class Thread02 {
public static void main(String[] args) {
Dog dog = new Dog();
Thread thread = new Thread(dog);
thread.start();
}
}
class Dog implements Runnable{
int num=0;
@Override
public void run() {
while (true){
System.out.println("hi"+(++num));
if(num==10)
break;
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
|
线程终止
线程完成任务之后会自动退出
通过方法停止线程
设置控制变量,在主线程去控制
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| public class ThreadExit_ {
public static void main(String[] args) throws InterruptedException {
T t = new T();
t.start();
Thread.sleep(6*1000);
t.setLoop(false);
}
}
class T extends Thread{
private int count=0;
private boolean loop=true;
public void setLoop(boolean loop) {
this.loop = loop;
}
@Override
public void run() {
super.run();
while(loop){
System.out.println("线程"+(++count)+"运行");
try {
Thread.sleep(50);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
|
线程常用方法
sleep:线程休眠
线程优先级范围
strat底层创建新线程
interrupt中断线程,一般用于中断正在休眠的线程
线程插队/礼让
yield: 礼让,主动让出cpu,但礼让的时间不确定,由cpu决定——静态方法Thread.yield()
join:让别人插队,是在被插的线程中调用,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| public class ThreadMethod02 {
public static void main(String[] args) throws InterruptedException {
T2 t2 = new T2();
t2.start();
for (int i = 1; i <=20 ; i++) {
System.out.println("主线程吃包子"+i);
Thread.sleep(50);
if(i==5){
System.out.println("让给子线程先执行");
Thread.yield();
}
}
}
}
class T2 extends Thread{
@Override
public void run() {
super.run();
for (int i = 1; i <= 20; i++) {
System.out.println("子线程吃包子"+i);
try {
Thread.sleep(50);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
|
守护线程和用户线程
把线程设置成守护线程——只要主线程结束了,这个线程也要结束
- 当所有的线程结束,守护线程也会结束
- 在线程开始之前就要设置成守护线程
生命周期和线程的七种状态
- new:刚开始创建线程,此时,线程对象已经存在,但是线程还没有开始运行,也没有占用任何系统资源
- Runable(可运行):调用
Thread.start()在可运行状态中,线程已经被线程调度器(Thread Scheduler)认定为可以被执行,但不一定马上执行,实际运行取决于操作系统的线程调度。
- TimeWaiting:睡眠,
- Waiting:被插队的线程会进入这个状态
- Blocked:阻塞,等待别的进程归还同步锁时,会归还此状态
- Terminated:线程终止,运行完毕
线程同步机制
- 在多线程编程中,一些敏感数据不允许别多个线程同时访问,同步技术保证数据在任意时刻,最多有一个线程访问,以此保护数据的完整性
- 使用
Synchr
同步代码块
IO流
创建文件的三种方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
@Test
public void create01(){
String filePath = "C:\\Users\\86135\\Desktop\\news.txt";
File file = new File(filePath);
try {
file.createNewFile();
System.out.println("创建成功");
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Test
public void create02(){
File parentfile = new File("C:\\Users\\86135\\Desktop");
String filename = "news.txt";
File file = new File(parentfile,filename);
try {
file.createNewFile();
System.out.println("创建成功");
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public void create03(){
String parentfile = "C:\\Users\\86135\\Desktop";
String filename = "news.txt";
File file = new File(parentfile,filename);
try {
file.createNewFile();
System.out.println("创建成功");
} catch (IOException e) {
throw new RuntimeException(e);
}
}
|
注意:
- 文件路径名的两种写法
\\或者/
- 创建文件对象只是暂时保存在内存中,
createNewFile才是将其写在硬盘上
查看文件相关信息:
1
2
3
4
5
6
7
8
9
10
| public void f1(){
File file = new File("d:\\test01.txt");
System.out.println(file.getAbsolutePath());
System.out.println(file.length());
System.out.println(file.isFile());
System.out.println(file.isDirectory());
System.out.println(file.exists());
System.out.println(file.getParent());
System.out.println(file.getName());
}
|
文件常用操作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
public void f3(){
String fileDictory="d:\\demo\\a\\b\\c";
File file = new File(fileDictory);
if(file.exists()){
System.out.println(fileDictory+"已存在");
}else{
if(file.mkdirs()){
System.out.println(fileDictory+"创建成功");
}else{
System.out.println(fileDictory+"创建失败");
}
}
}
|
IO流原理
- 文件流分为字节流(8 bit, 二进制文件无损)和字符流,字节流以字节为传输单位,适用于二进制文件,字符流以字符为单位,根据不同的编码方式字符单位的大小也不同,适用于文件传输
- 输出方向上分为输入流和输出流,输入流指由文件->控制台输出,输出流指由控制台->文件
|
字节流 |
字符流 |
| 输入流 |
InputStream |
Reader |
| 输出流 |
OutputStream |
Writer |
| 上面这四个类衍生出一系列类,它们是最根本的,但它们都是抽象类,需要其子类来实现其方法 |
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public void test1() {
String path = "C:\\Users\\86135\\Desktop\\news.txt";
int readData = 0;
FileInputStream fis = null;
try {
fis = new FileInputStream(path);
while ((readData = fis.read()) != -1)
{
System.out.print((char)readData);
}
} catch (IOException e) {
throw new RuntimeException(e);
}finally {
try {
fis.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
|
字符流:(文本文件)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
public void readf1(){
FileReader fileReader=null;
int data=0;
String path="D:\\story.txt";
try {
fileReader=new FileReader(path);
while((data=fileReader.read())!=-1){
System.out.print((char)data);
}
} catch (IOException e) {
throw new RuntimeException(e);
} finally {
try {
fileReader.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
@Test
public void readf2(){
FileReader fileReader=null;
char[] data=new char[8];
int len=0;
String path="D:\\story.txt";
try {
fileReader=new FileReader(path);
while((len=fileReader.read(data))!=-1){
System.out.print(new String(data,0,len));
}
} catch (IOException e) {
throw new RuntimeException(e);
} finally {
try {
fileReader.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
public void f1(){
FileWriter fileWriter=null;
String path="d:\\note.txt";
char[] data={'h','j'};
try {
fileWriter=new FileWriter(path,true);
fileWriter.write('H');
fileWriter.write("哈哈哈哈");
fileWriter.write("你好解耦",0,2);
fileWriter.write(data,0,1);
} catch (IOException e) {
throw new RuntimeException(e);
} finally {
try {
fileWriter.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
|
节点流和处理流
节点流:直接连接数据源,执行基础的读写操作
处理流:封装了节点流,能够叠加在节点流之上,拓展流的功能(缓冲,数据类型转换)
BufferReader 和 BufferWriter ——字符处理流
字符处理流
BufferReader:
实体化时包装类Reader类,根据实际需要可以接收Reader的子类,也就实现了对不同文件的类型的操作
![[Pasted image 20241025203815.png]]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
| public class BufferReader01 {
public static void main(String[] args) {
String filepath="d:\\story.txt";
BufferedReader bufferedReader=null;
try {
bufferedReader = new BufferedReader(new FileReader(filepath));
String line=null;
while((line=bufferedReader.readLine())!=null){
System.out.println(line);
}
} catch (IOException e) {
throw new RuntimeException(e);
} finally {
try {
bufferedReader.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
}
public class BufferWriter01 {
public static void main(String[] args) throws IOException {
String path="d:\\ok.txt";
BufferedWriter bufferedWriter = new BufferedWriter(new FileWriter(path,true));
bufferedWriter.write("你好");
bufferedWriter.newLine();
bufferedWriter.write("syx");
bufferedWriter.newLine();
bufferedWriter.close();
}
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public class BufferCopy02 { \\ 复制就是读入后 写出
public static void main(String[] args) throws IOException {
String srcpath="D:\\JUST\\研1\\分享资料\\bhg.png";
String despath="D:\\bhg.png";
byte[] data=new byte[1024];
int len=0;
BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream(srcpath));
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(new FileOutputStream(despath));
while((len=bufferedInputStream.read(data))!=-1){
bufferedOutputStream.write(data,0,len);
}
bufferedInputStream.close();
bufferedOutputStream.close();
}
}
|
- 存储数据时,一般的存储只存储了数据,要将文件进行如恢复的操作还需要知道对应的数据类型,这种将数据及其类型进行存储的方式叫做序列化,反之称为反序列化。
- 也就出现了将数据进行对象形式传输的方法,根据输入和输出分为ObjectOutputStream和ObjectInputStream
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| public class ObjectOutputStream_ {
public static void main(String[] args) throws Exception {
String path="d:\\data.dat";
ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream(path));
objectOutputStream.writeInt(1);
objectOutputStream.writeBoolean(true);
objectOutputStream.writeDouble(0.9);
objectOutputStream.writeUTF("hello");
objectOutputStream.writeObject(new Dog(10,"hxy","白色",2));
objectOutputStream.close();
}
}
public class Dog implements Serializable {
private int age;
private String name;
private static final long serialVersionUID=1;
private transient String color;
private static int add;
public Dog(int age, String name,String color,int add) {
this.age = age;
this.name = name;
this.color=color;
this.add=add;
}
@Override
public String toString() {
return "Dog{" +
"age=" + age +
", name='" + name + '\'' +
'}'+color+add;
}
public void shout(){
System.out.println("goujiao");
}
}
|
ObjectInputStream
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| public class ObjectInputStream_ {
public static void main(String[] args) throws Exception {
String path="d:\\data.dat";
ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream(path));
System.out.println(objectInputStream.readInt());
System.out.println(objectInputStream.readBoolean());
System.out.println(objectInputStream.readDouble());
System.out.println(objectInputStream.readUTF());
Object object = objectInputStream.readObject();
System.out.println(object.getClass());
System.out.println(object);
Dog dog=(Dog)object;
dog.shout();
}
}
|
注意:
- 序列化的前提是这个数据类型或者类实现了
Serializable这个接口,即可序列化
- 读取文件中的序列化数据(反序列化)要按照序列化的顺序进行反序列化
- 带有
terminant和static修饰的属性是不会进入序列化的
- 若自定义类中有所改动,则反序列化会失败,要重新序列化才可以。另外一个办法是在自定义类中加上
private final long seriaVersionUID这个属性,表示版本号
标准输入输出流
System.out 是输出流,编译和运行类型都是PrintStream
System.in 是输入流,编译类型是InputStream,运行类型是BufferedInputStream
字节流 -> 字符流 转换流
文件存在编码问题需要进行转换
- 输入转换InputStreamReader
- 将字节流转换成字符流
- ![[Pasted image 20241028153732.png]]
- 构造器第一个参数是inputstream类及其子类,第二个参数是编码类型
输出流类似OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(path), "utf8");
字节输出流PrintStream
System.out是输出到控制台的,可以通过设置输出的地址输出到不同的地方
1
2
3
4
5
6
7
8
9
10
11
|
PrintStream out=System.out;
out.println("hello");
out.write("hello".getBytes());
System.setOut(new PrintStream("d:\\f1.txt"));
System.out.println("hellosyx");
PrintStream printStream = new PrintStream(new FileOutputStream("d:\\f2.txt"));
printStream.println("hhhh");
|
字符输出流PrintWriter
1
2
3
| PrintWriter printWriter = new PrintWriter(new FileWriter("d:\\f3.txt"));
printWriter.println("字符输入流");
printWriter.close();
|
配置文件 Properties
- Properties类操作的文件内容必须是有=号的,即“键”=“值” 等号两边没有空格
读取文件
1
2
3
4
5
6
7
8
|
Properties properties = new Properties();
properties.load(new FileReader("src//mysql.properties"));
properties.list(System.out);
String user = properties.getProperty("users");
System.out.println(user);
|
修改存储文件
1
2
3
4
| Properties properties = new Properties();
properties.setProperty("add","wanke");
properties.setProperty("phone","11234");
properties.store(new FileWriter("src\\mysql02.properties"),null);
|
网络编程
在网络开发中不要使用0-1024的端口
域名:www.baidu.com dns IP映射成域名,域名好记
协议就是网络编程中数据组织的形式,如josh数据?
Socket 数据连接
TCP 字节流
服务端:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
ServerSocket serverSocket = new ServerSocket(9999);
System.out.println("等待9999端口的消息传送...");
Socket accept = serverSocket.accept();
System.out.println(accept.getClass());
InputStream inputStream = accept.getInputStream();
byte[] data=new byte[1024];
int line=0;
while((line=inputStream.read(data))!=-1){
System.out.println(new String(data,0,line));
}
OutputStream outputStream = accept.getOutputStream();
outputStream.write("hello,client".getBytes());
accept.shutdownOutput();
outputStream.close();
inputStream.close();
serverSocket.close();
System.out.println("服务端已关闭");
|
服务端使用SeverSocket类在端监听,若有连接通过serverSocket.accept()方法得到Socket类并建立会话关系,Socket类进行数据的获取
客户端
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
Socket socket = new Socket(InetAddress.getLocalHost(), 9999);
OutputStream outputStream = socket.getOutputStream();
outputStream.write("hello.server".getBytes());
socket.shutdownOutput();
InputStream inputStream = socket.getInputStream();
byte[] data=new byte[1024];
int line=0;
while((line=inputStream.read(data))!=-1){
System.out.println(new String(data,0,line));
}
inputStream.close();
outputStream.close();
socket.close();
|
需注意,两端并不知道对方何时数据传输结束,需在自己方设置socket.shutdownOutput();表示写入结束。否则在第一段通话结束后,陷入等待
TCP 字符流
字符流传输就是在昨天的字节流传输的基础上,进行字节流->字符流的转换操作
服务端
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
ServerSocket serverSocket = new ServerSocket(9999);
System.out.println("等待9999端口的消息传送...");
Socket accept = serverSocket.accept();
System.out.println(accept.getClass());
InputStream inputStream = accept.getInputStream();
String data=null;
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream));
data=bufferedReader.readLine();
System.out.println(data);
OutputStream outputStream = accept.getOutputStream();
BufferedWriter bufferedWriter = new BufferedWriter(new OutputStreamWriter(outputStream));
bufferedWriter.write("hello,client");
bufferedWriter.newLine();
bufferedWriter.flush();
bufferedWriter.close();
bufferedReader.close();
serverSocket.close();
System.out.println("服务端已关闭");
|
客户端
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
Socket socket = new Socket(InetAddress.getLocalHost(), 9999);
OutputStream outputStream = socket.getOutputStream();
BufferedWriter bufferedWriter = new BufferedWriter(new OutputStreamWriter(outputStream));
bufferedWriter.write("hello,server");
bufferedWriter.newLine();
bufferedWriter.flush();
InputStream inputStream = socket.getInputStream();
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream));
String data=null;
data=bufferedReader.readLine();
System.out.println(data);
bufferedWriter.close();
bufferedReader.close();
socket.close();
|
注意:
在字符流中用newline()表示当前输出结束
输出结束后要用flush()方法才能成功输出内容
接受的一方要用readline()来读出内容
TCP图像传输
首先知道图像是一个二进制文件,所以用字节流
- 新建输入流根据具体路径获得文件数据,存储在字节数组中
- 在客户端新建Socket的输出流,将文件输出
- 服务端接收,获取Socket的输入流,获取文件的字节数组
- 服务器新建输出流,将获取的字节数组转化为文件存储到指定路径
服务端
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
ServerSocket serverSocket = new ServerSocket(8888);
Socket socket = serverSocket.accept();
InputStream inputStream = socket.getInputStream();
byte[] bytes = StreamUtils.streamToByteArray(inputStream);
String path="src\\bg.png";
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(new FileOutputStream(path));
bufferedOutputStream.write(bytes);
bufferedOutputStream.close();
inputStream.close();
socket.close();
|
客户端
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| Socket socket = new Socket(InetAddress.getLocalHost(), 8888);
String path="d:\\bhg.png";
BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream(path));
byte[] bytes = StreamUtils.streamToByteArray(bufferedInputStream);
OutputStream outputStream = socket.getOutputStream();
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(outputStream);
bufferedOutputStream.write(bytes);
socket.shutdownOutput();
bufferedOutputStream.close();
bufferedInputStream.close();
socket.close();
|
反射
动态加载和静态加载
静态加载:在编译的时候就检查
动态加载:没用到就不会报错
反射是动态加载,原始方法 new 类是静态加载
类加载三个阶段:加载 连接 初始化(静态变量初始化)
连接阶段:验证-准备-解析
验证安全性 解析:把符号引用变成真正的地址引用
